快讯:linkedin CEO 宣布以15亿美元收购在线学习网站Lynda美国职业社交网站LinkedIn今日宣布,将以约15亿美元收购在线学习网站Lynda.com。
Lynda.com总部位于加州,拥有550名员工,由琳达·威曼(Lynda Weinman)和布鲁斯·海文(Bruce Heavin)共同创办。公司专门制作在线学习工具,并将其出售给个人和大企业客户。
Lynda.com提供逾5700项课程和25.5万段视频辅导。注册后,会员便可以访问这些课程。这些课程支持英语、德国、法语、西班牙语和日语。
LinkedIn CEO杰夫·维纳(Jeff Weiner)称:“LinkedIn和Lynda.com的使命高度一致,都是为了帮助专业人士更好地做好本职工作。”
该交易将以现金加股票形式进行,其中现金占约52%,股票部分占约48%。据预计,该交易将于本季度内完成。
琳达·威曼(Lynda Weinman) 的博文:
Today, I am thrilled to share the exciting news that lynda.com hasentered into an agreement to be acquired by LinkedIn. Our story is one only possible in the Internet age, and it has been an unbelievable journey that proves just how much people have come to value and embrace new ways to learn new skills.
As a teacher, entrepreneur and lifelong learner, this is a very exciting moment in my own professional journey. Early on in my career, as a teacher at Art Center College of Design in Pasadena, I found my passion and talent for de-mystifying design software for my technology-phobic art students. In 1995, I secured the domain lynda.com as a sandbox from which to teach web publishing. I wrote my first book in 1996, with invaluable help from my husband Bruce Heavin, called Designing Web Graphics, and never dreamed that it would become an international bestseller.
Although the platform has changed—from in-person teaching at our small school in Ojai, California, to courses on VHS, DVD and later the Internet—from the start, lynda.com became known for our friendly, approachable teaching style. We have always focused on making lynda.com flexible enabling people to learn from anywhere, at their own pace and on their own schedules.
When we were approached by LinkedIn, we instantly recognized that the synergy between the two companies offered a match unlike any other. LinkedIn has the largest database of professionals in the world, all of whom potentially benefit from self-paced study of new skills. Jeff Weiner, CEO of LinkedIn, and I both believe that the skills gap is one of the leading social issues of our time—technology, changes fast and people need to keep their skills up to date. We have a shared vision of connecting relevant knowledge to those in need of new or stronger skills, and believe that together we can positively impact the global job market and economy.
This is a moment in history when people can learn anytime, anywhere, and with no boundaries. We believe in LinkedIn’s future stewardship and vision, and feel that we have found a perfect cultural fit for our mission. We are thrilled to be part of something bigger than ourselves, and look forward to helping more people learn the skills that are needed in today’s rapidly changing economic landscape.
Congratulations to the entire lynda team, and here’s a toast to people everywhere who are motivated and empowered to learn new skills. Thank you to all of our members who have supported and contributed to our success.
Caliber 推出面向职场人士的消息应用
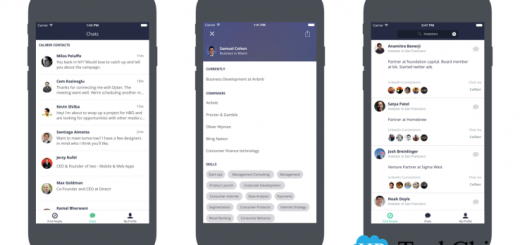
过去多年,在 LinkedIn 的阴影下,多家创业公司试图提供新方式,尤其是基于移动端的方式,帮助企业员工相互通信,发掘企业市场的某些细分领域。今天,一款名为 Caliber 的新应用带来了一些不同之处:该应用并未试图与 LinkedIn 直接竞争,而是提供了一款互补的工具,一方面帮助用户与当前的 LinkedIn 联系人聊天,而另一方面则帮助用户扩大自己的职场关系网,同时屏蔽掉垃圾消息。
Caliber 推出于 去年夏季 ,最初是一款类似 Tinder 风格的应用,帮助人们建立职业联系。该公司首席执行官安德里斯·布兰科(Andres Blank)表示,最初这款应用的用户数已达到 2 万,但 Caliber 的团队随后意识到,用户真正想要的并不是这样的模式。用户不只需要联系感兴趣的人,还希望能向职业联系人发送消息。
不过,开发面向商业用途的消息应用也有着自身的困难。用户需要创建包含职业信息的帐号,在平台上搜索并查找适当的联系人。而最重要的是,这样的应用需要避免垃圾消息的泛滥。
我发现,专注于这一领域的许多其他应用都遭遇了垃圾消息的困扰。创业公司开发有趣的社交体验,帮助企业员工建立联系,但垃圾消息似乎很难得到控制。
如果你的建议和观点很有价值,或者说别人有求于你,例如你是一名颇有成就的风险投资家,那么你将会收到大量的好友请求。无论加入什么平台,你都会收到许多这类消息。对这样的用户来说,参与这种平台将变得困难,甚至导致他们不想参与这些平台。
关于 Caliber,有趣的一点在于,该公司的解决方案专注于解决上述问题。
这款应用的用户帐号基于 LinkedIn,因此可以了解用户之间的职业社交关系。如果两名用户已经是 LinkedIn 联系人,并且同时使用 Caliber,那么就可以在这一应用中互发消息。而如果其中只有一人使用 Caliber,那么 Caliber 用户可以通过该应用发送 LinkedIn 站内信给非 Caliber 用户。如果双方并没有在 LinkedIn 上建立联系,那么用户可以通过 Caliber 发送加好友请求。
此外,与大部分社交应用不同,当有消息到来时,这款应用并不会立即向用户发送推送通知。因此,你不必为回应烦人的推送通知而苦恼。在一星期末,Caliber 会将用户收到的请求汇总并进行排序,随后再呈现给用户。用户的 LinkedIn 联系人,以及 Caliber 中的热门人物会出现在这一汇总清单的前列。因此,用户可以更好地决定与谁建立好友关系,并知道为何要建立这样的关系。
与 LinkedIn、Facebook,以及大部分社交网络不同,所有未回应的请求将会在一周时间后消失。
这并不会阻止他人再次尝试加为好友。不过,这一举措能使加好友流程更加智能、更加简单。
与此同时,如果你需要扩大自己的职场关系网,那么可以通过 Caliber,基于人们的职业经历,例如职位、技能和公司,来查找其他用户。
目前,Caliber 应用仅支持联系人之间的消息发送,而未来,该团队还希望支持视频通话、文件共享,以及会议活动邀请等功能,并将支持的社交网络扩大至 Twitter 和 AngelList。最终,该公司希望通过企业级功能获得收入,例如与客户关系管理(CRM)系统的连接,帮助企业招聘者或人力资源经理获得数据,以更好地招到专业人才。
不过,Caliber 也存在一个潜在的问题。该应用基于 LinkedIn,而后者以往似乎不太愿意支持第三方应用生态系统。例如近期,LinkedIn 宣布 只向合作伙伴开放完整的应用程序接口(API)。Caliber 正在申请成为 LinkedIn 的合作伙伴,但目前尚未成功。不过布兰科仍对此充满希望。
“从短期来看,可以说,我们的服务和 LinkedIn 站内信之间有些许相似之处。不过从长期来看,我们将成为一款单纯的通信应用。”他表示,“LinkedIn 更多地关注用户的身份和简历。我认为,我们可以与他们互补,同时也为他们的平台做出贡献。”他指出,Caliber 可以帮助人们在 LinkedIn 上建立联系。
目前,Caliber 团队位于纽约,共有 5 名成员,正在完成种子轮融资。布兰科也是 一名天使投资人,曾成功创立并 出售 Pixable。除他之外,该公司的其他创始人还包括 TechStars 成员克里斯·卡尔梅恩(Chris Calmeyn)。他此前曾是 Piictu 的负责人,以及 Travelocity 的产品经理。
目前,这款新应用可以 通过 iOS 和安卓平台下载 。
Caliber Debuts A Messaging App Designed For Business Professionals
A number of startups in years past have tried to carve out their own niche in the business networking space under the looming shadow of LinkedIn by offering an alternative way to connect with industry colleagues, often on mobile. But today, a new app called Caliber is offering a slightly different take on the concept: instead of trying to compete with LinkedIn directly, its service offers a complementary tool that lets you chat with your LinkedIn contacts as well as grow your network without being overrun by request spam.
Caliber itself first launched last summer, but initially offered a Tinder-like app for making business connections. That app grew to 20,000 users, but the team realized that it wasn’t quite what people wanted. Users didn’t want to just connect with other interesting people, they wanted to be able to reach their business contacts and message them, explains company co-founder and CEO Andres Blank.
However, building a messaging app for business use presents its own sorts of challenges. Users have to create accounts that include their professional identities, they need to be able to search for and find the right people on the platform, and most importantly, the app needs to be careful to not encourage spam.
That latter problem is something I’ve seen a number of other attempts in this space gloss over – startups would create these interesting social experiences for connecting industry colleagues, but they would never address the issue of spam.
That is, when you’re someone whose advice or insight is valuable, or you’re someone who’s in demand – think, for example, a VC getting hundreds of pitches from entrepreneurs – you become overwhelmed by the number of requests to connect or incoming messages on any platform you join. For these sought-after users, the problem makes it difficult for you to participate, and it even discourages you from doing so.
What’s interesting about Caliber is that it has focused on developing a solution to this problem.
The app leverages LinkedIn to build out its user profiles and understand who’s connected to who. If two people are already LinkedIn connections and are both on Caliber, they can message each other in the app. If they’re connected on LinkedIn, but only one person uses the app, the app lets you send a LinkedIn InMail to the non-Caliber user. And if both users are not connected on LinkedIn, one user can send a request to connect with the other on Caliber instead.
But the app doesn’t barrage users with requests the minute they come in like most social apps do. There aren’t buzzy push notifications forcing to you to respond to each incoming invite. Rather, at the end of the week, Caliber presents a list of your requests and it ranks them for you, showing those first where you have mutual connections or the person is popular within the app. This allows you to make better decisions about who to connect to, and why.
Then, unlike on LinkedIn or Facebook or most other social networks, all the unanswered requests just disappear after a week’s time.
That doesn’t prevent those same users from trying again later, but it does make the process of growing your network – smartly – a lot easier.
Meanwhile, if you’re the one in need of expanding your network, you can use Caliber to seek out users based on their professional experience, including their roles, skills and companies.
Currently, the Caliber app only enables messaging between contacts, but in the future, the team wants to expand the app to support things like video calls, file sharing or appointment scheduling, as well as connecting to contacts on other networks, like Twitter or AngelList, for example . And eventually, it wants to generate revenue through business-level features, like support for connecting with CRM systems, or the ability to generate data that could help recruiters or hiring managers find in-demand professionals.
One potential problem Caliber could face, however, is that it’s being built on top of LinkedIn – a company which doesn’t have a good history with regard to supporting its ecosystem of third-party apps. For instance, it recently began limiting full API usage only to partners. Caliber is applying for partnership status, but hasn’t been granted this yet. However, Blank is hopeful.
“Right now in the short-term, you could say there are some similarities [between us and what LinkedIn] does with InMail, but in the long-term, we’re a pure communications app,” he says. “LinkedIn is much more about identity. It’s about your resumé…I think we’re complementary to them and we also give back to their platform,” Blank notes, adding that Caliber can help people establish a connection on LinkedIn, too.
The company is a team of five based in New York and is now closing a seed round. In addition to CEO Blank, an angel investor who previously founded and sold Pixable, the startup is co-founded by Chris Calmeyn, a TechStars alum and previously head of product at Piictu and a product manager at Travelocity.
The new app is available for both iOS and Android.
来源:techcrunch.cn
扫一扫,关注“HRTechChina",聆听人力资源科技的声音!
linkedin
2015年03月27日
linkedin
LinkedIn确认收购招聘推荐软件Careerify
拥有超过 3 亿用户的 LinkedIn 昨日宣布收购总部位于多伦多的 Careerify。公司成立于 2009 年,已有不少企业在使用 Careerify,其中包括 Deloitte, Groupon, Microsoft, SpaceX 和 Unilever。
Careerify 是款招聘推荐软件,可通过抓取员工的社交网络信息(像 LinkedIn、Twitter 和 Facebook),来发现他们的朋友适合公司的哪些工作职位。换言之,就是通过覆盖更大的人脉网络来帮助企业完成招聘工作。除此之外,Careerify 能及时通知本公司的员工,告诉他们公司有哪些新开放的职位,有助于将好的人才留住。
以下为Careerify创始人及首席执行官Harpaul Sambhi在其官网上发布的一封信件:
招聘推荐软件Careerify成立之初就心怀远大梦想:消除全球失业的同时让客户更有利可图更有策略。而如今,我很高兴的告知各位,我们被linkedin收购了(我们决定加入linkedin)。
我们创业之初恰逢最萧条的年代,那时候数以百万计找工作的人的求职经历用大海捞针来形容一点也不为过。于是,我们提出相应的解决方案,通过抓取员工的社交网络信息,以此找寻并及时推荐适合公司空缺公开职位的最佳人选。
加入linkedin,是因为我们缺乏它那样的大数据。全球有大约超过三万多家公司的招聘是受linkedin的影响,仅注册人数就有三亿四千七百万,这么庞大的用户群可以让领英在求职招聘中发挥更大的影响。我们非常兴奋能加入linkedin,这样可以提高我们的技术,能接触更大范围的人才。
与linkedin合作,Careerify不仅仅是专注内部流动性和招聘品牌,我们会更专注于更新人员推荐软件,为已有用户提供更好的服务,不再接收新用户。
回首过去,我们做出的这般惊人成就得益于广大用户,谢谢你们无条件的支持,我们才走到今天这一步。这些年来你们的长久追随和信任我们的目标,对此我们表示深深的感谢。
就如俗话说的那样:事业与激情的结合是多么美好的事情啊!我们期待与领英团队的合作,来帮助用户找到他们梦寐以求的工作,找到与职位最匹配的人。
祝好!
Harpaul Sambhi
Careerify 创始人及首席执行官
The Next Frontier: Careerify Joins LinkedIn
Careerify was founded with a bold mission: to eradicate unemployment globally while making our clients more profitable and strategic. Today, I’m happy to share that we’ve been acquired by LinkedIn.
We started this business during one of the worst recessions of our time, where the term ‘needle in a haystack’ reflected the job search experience for millions of candidates. In response, we developed a referral solution that looked at open jobs within an organization and scanned its employees’ connections on social networks in real-time to pinpoint the perfect candidate.
We decided to join LinkedIn due to what we lacked – massive scale. More than 30,000 companies across the globe leverage LinkedIn for recruitment, and with more than 347 million members, LinkedIn offers an opportunity to make a much larger impact on job seeking and hiring. We are absolutely thrilled to be joining LinkedIn to accelerate our technology and connect talent with opportunity on a massive scale.
As we work with LinkedIn, Careerify will no longer focus its efforts on internal mobility and employer branding. We’ll focus purely on further improving our employee referral software for existing customers, and will not be taking on new customers.
Reflecting on this incredible journey, we would like to thank our customers for their unbelievable support. You stood by us and believed in our mission throughout the years and there are simply no words to express our gratitude for that.
As the saying goes, “It’s a beautiful thing when career and passion come together.” We look forward to working with the LinkedIn team to help people find their dream jobs, and jobs find the right people.
All the best,
Harpaul Sambhi
Careerify Founder and CEO
扫一扫,关注“ HRTechChina “,聆听人力资源科技的声音!

 linkedin
linkedin
 linkedin
linkedin
 linkedin
linkedin
 linkedin
linkedin
 linkedin
linkedin

 linkedin
linkedin
 linkedin
linkedin
 linkedin
linkedin
 linkedin
linkedin
 linkedin
linkedin



 扫一扫 加微信
hrtechchina
扫一扫 加微信
hrtechchina

