走进估值 200 亿美金的大数据龙头企业 Palantir
当前世界最为领先的反恐秘密武器非Palantir莫属,这间全球排名第一的大数据公司Palantir早在2004年便已成立,公司注册在美国的特拉华州,由Facebook的早期投资人、PayPal的联合创始人皮特·泰尔(Peter Thiel),和其他四个人联合创立的,其中就包括了现在的首席执行官阿历克斯·卡普(Alex Karp)。
皮特·泰尔1998年创立Paypal, 2002年以15亿美元卖给Ebay。 Paypal非常受商家欢迎, 也受到犯罪分子青睐,他们利用Paypal进行洗钱和诈骗。 之后他们于2004年创立Palantir决定把Paypal的防止欺诈技术商业化,并建立一个数据分析的模型, 用PayPal安全认证系统的人机复合模式来辨识恐怖分子和金融诈骗。
运用Palantir提供的分析软件,分析师还可以预测阿富汗的叛乱分子放置爆炸装置的地点,帮助起诉引人注目的内幕交易案件,打击全球最大的儿童色情团伙,以及通过先进的诈骗检测软件,帮助商业银行每年减少上亿美元的损失。洛杉矶警察局的警探用它进行案件侦破,摩根大通行用Palantir的系统识别了诈骗分子。
银行运用Palantir揭露内部工作人员的可疑行为并追查资金去处:
它是如何工作的?
这家公司的名字来自《指环王》里的“视眼(Palantir)石”,这种石头可以帮助剧中人物和其它石头建立联系,从而可以看到附近的图像。Palantir的基本要点就是收集大量数据,帮助非科技用户发现关键联系,并最终找到复杂问题的答案。该产品源自PayPal,最初用做反欺诈措施:“他们遇到了这种严重的网络欺诈行为……他们尝试了种种算法……但问题之一是效果并不理想,因为对手非常灵活……你需要的是一个灵活的头脑,”Karp解释说。
这为Palantir平台奠定了基础,该平台把人工算法和强大的引擎(可以同时扫描多个数据库)整合到了几近完美的境界。
采访洛杉矶警官关于Palantir在破案时的运用:
Palantir客户背景:
目前该公司业务大多来自政府、银行、保险、零售、医疗保健、石油和天然气等行业。很多金融机构购买Palantir来调查金融诈骗。例如美国银行,美国证监会,对冲基金等。Palantir在2014年仅企业级用户已突破14000家!
Palantir 的业务遍布全球,并非只局限于美国。在新加坡,加拿大,澳大利亚,欧洲均有办公室。
(图片来源:Palantir官网截图)
Palantir 早已成为美国政府御用的分析机构,CIA、FBI、海陆空三军以及纽约和洛杉矶警察局等都是Palantir的客户。根据USAspending.gov网站上的数据,自2009年以来,Palantir已经从FBI、国防部和国土安全部获得了超过3亿美元的合同。
(图片来源:网络)
Palantir 财务状况以及过往融资情况
据消息,该公司目前在银行的现金超过10亿美元。公司已经手握大量现金,筹集更多资金,以保护自己免受任何未来可能出现的经济低迷形势的冲击。
Palantir在早期获得了美国中情局(CIA)旗下的投资机构In-Q-Tel 200万美金的融资,之后接受了彼得·蒂尔创办的风险投资基金Founders Fund 3000万美元的投资。
2010年7月,融资9000万美元投资,公司估值7.37亿美元。
2011年5月6日,融资5000万美元,累计融资额达到了1.75亿美元。
2011年10月7日,融资7000万美元,估值25亿美元。
2013年9月29日,融资1.96亿美元,估值60亿美元。
2013年12月12日,融资1.075亿美元,估值90亿美元。
2014年,估值达90亿美元。
2015年,融资5亿美元,估值达200亿美元。
累计融资达16亿美金。
目前,彼得·蒂尔是这家公司的最大股东。在刚结束的一轮5亿美金融资中,Palantir获得了200亿美金的估值,成为Uber、Airbnb之后全美估值第三高的创业公司。当然,高估值是由亮眼的业绩支撑的,去年全年,Palantir的销售额达到了10亿美元。Palantir 目前把大量的利润都投入再研发,为的是未来承担更大的历史使命和责任,同时获取更大的市场和利润。
通常购买Palantir软件的费用在500万美元至1000万美元之间,客户被要求预先支付20%的经费,剩余部分在客户满意后在支付。至今没有一套软件因为质量问题被退回。其创始人Alex Karp声称公司是“没有公关,没有销售,没有营销”,而这一切都是为了保证产品。
Palantir今年初收购了零售大数据Fancy That等, 全力进军零售大数据领域。预计零售大数据将会给Palantir带来爆发式的增长。虽然Palantir垄断了美国政府业务,但随着其他领域业务的爆发式的增长,政府业务的占比将进一步下降。
Palantir的投资者
Palantir有138家风投,其中包括很多著名投资机构及个人,例如:
TIGER GLOBAL (老虎基金)
Black Rock (全球最大的资管公司贝莱德)
THE FOUNDERS FUND (Peter Thiel 旗下的基金)
Credit Suisse FirstBoston Next Fund, Inc.
In-Q-Tel, Inc. (中情局旗下的风投机构)
The Founders Fund, LP
Kenneth Langone
Stanley Druckenmiller
随着我国网络传输能力的不段增强,信息安全的不段重视,打造中国版的Palantir迫在眉睫。大数据的时代的来临更需要的是软件算法能力的加强,而非简单机械化硬件的布局。我们预计未来3-5年内,中国信息安全产业将保持30%以上的增长,行业增速增长趋势明显,并且具备极高的准入门槛。中国现在有些公司像烽火通信,蓝灯科技等等都往打造中国版的Palantir发展, 谁会成为中国市场上真正的Palantir, 我们拭目以待!
摘自:环球理财
大数据
2015年08月11日
大数据
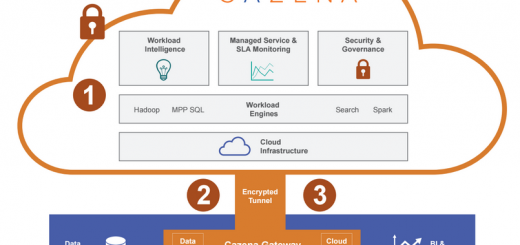
大数据服务平台Cazena获2000万美元B轮融资Cazena,一家帮助企业处理数据的新平台,今天宣布已获2000万美元B轮融资,融资由Formation 8领投。其他的投资方包括Andreessen Horowitz和North Bridge Venture Partners,他们也参与了去年十月Cazena800万美元的A轮融资。
Cazena由部分Netezza的前任员工创办,Prat Moghe是公司的领头人。2010年Netezza被IBM收购时,他担任数据监察部门总经理,收购后,任职高级副总裁,负责产品、战略和市场营销。
在IBM干了一段时间后,Moghe觉得是时候用新的视角来解决Netezza曾遭遇的一些问题了。“在看到企业都是如何同全新的大数据堆栈(如Hadoop,一种分布式系统基础架构)挣扎较劲的情况下,我们开始思考下一个十年数据处理的前景,”他说道。“每一个企业,尤其是中大型企业,都在积极寻找着能提高进程灵敏度的云方法,但是现有平台的复杂性和安全问题是很大的障碍。”
Cazena 的目标是极大简化商业中的大数据进程处理。Moghe设想,最终的理想状态是,使用Cazena时只需点三下,就能设置好数据处理工作(当然现阶段还有一些问题需要解决)。
这项服务通过自动搜寻到,处理设定数据组的分析技术方案,从而解决掉处理的复杂性。接下来,它会替客户自动的规定、优化和管理工作流程,无论是Hadoop、Spark、MPP还是SQL9(如Amazon Redshift)类型的结构。
根据你的工作量和其他标准,如价格或是你想要获得结果的速度,Cazena会为你提供适当的基础结构,然后全程关注进度。“最终,数据即服务成为一个新的分类,我们希望能助企业一臂之力,让他们用好云计算。”
Cazena花费了约两年的时间,才公开他们的新产品。但Moghe说,公司尚在和一小部分大型企业合作,进行β测试,现在还没有达到完全开放服务的阶段。
当准备就绪的时候,Cazena会使用相对特别的定价计划。Moghe说,计划是针对服务,包括所有的云计算成本、支持和SLA开销,收取单一费用。他认为,目前针对云处理的收费系统,如gigabyte、note,对企业而言结果都太难预测。
公司的这一轮融资资金,将会用于技术开发、销售推广和合作伙伴建设。
Cazena Raises $20M Series B For Its Enterprise Big Data-As-A-Service Platform
Cazena, a new platform that wants to make it easier for enterprises to process their data, today announced that it has raised a $20 million Series B round led by Formation 8. Other participants include Andreessen Horowitz and North Bridge Venture Partners, who both also participated in the company’s $8 million series A round last October.
Cazena was founded by a number of former Netezza employees and is now led by Prat Moghe, who was Netezza’s general manager for data compliance before its acquisition by IBM in 2010. He then became the senior vice president for strategy, product and marketing at Netezza under IBM’s ownership.
After a few years at IBM, Moghe decided that it was time to look at some of the problems Netezza was trying to solve from a fresh perspective. “We started thinking about the next decade of data processing and how enterprises are struggling with the new big data stacks like Hadoop,” he told us. “Every enterprise — and particular the medium to large enterprises — they were actively looking at the cloud to speed up the agility of processing. But they were being held back by the complexity and security issues [of the existing platforms].”
Cazena aims to greatly simplify big data processing for businesses. Ideally, it should only take three clicks to set up a data processing job with Cazena, Moghe believes (though in reality, it’s still a bit more involved right now). The service strips away the complexities by trying to automatically figure out what technology to use to analyze a given set of data. It then automatically provisions, optimizes and manages that workflow for its customers, no matter whether it’s a Hadoop, Spark or MPP SQL (think Amazon Redshift) job.
Depending on your workload and other criteria like price or how fast you need the results, Cazena will provision the right infrastructure for you and then take care of the processing. “Ultimately, data as a service is a new category and we want to help big enterprises get into the cloud,” Moghe said.
It took the Cazena about two years to get to this point where it’s openly talking about the new product. But while Moghe told me that the company is already running some beta tests with a small number of large companies, Cazena isn’t quite ready to open up its service to all yet.
Once it does launch, though, it will do so with a relatively unusual pricing plan. Moghe tells me that the plan is to charge a single fee for the service that will include all of the cloud costs, support and an SLA. He argues that current cloud processing systems that charge by gigabyte or node are too unpredictable for enterprises.
The new funding the company announced today will go toward building out the company’s technology, sales force and partnerships.
来源:tc
大数据
2015年07月23日
大数据
微软新推出套件集合大数据和分析工具
微软在奥兰多举行的全球合作伙伴大会上宣布了 Cortana Analytics Suite。 它将该公司的机器学习、大数据和分析产品都集合到一个完全统一的套件中
微软寄希望于该套件能够为企业用户提供一站式的大数据和分析解决方案。
微软负责 Azure 机器学习的企业副总裁约瑟夫·斯瑞西(Joseph Sirosh)告诉 TechCrunch,“我们的目的是将这些分散的部分集成在一起,这样用户就可以有一个完整的平台来搭建智能解决方案。”
至于 Cortana,这是微软在 Windows 10 中推出的语音驱动的个人助理工具,只是解决方案的一小部分,不过斯瑞西表示,微软以 Cortana 来命名这个套件是因为它象征着微软公司希望通过这个套件提供的符合实际的智能。
这个套件汇聚了微软的云机器学习产品 Azure ML、数据可视化工具 PowerBI 和上周宣布的企业数据共享和数据存储访问服务 Azure Data Catalog 等等。微软希望利用脸部和语音识别等一系列技术来生成推荐引擎和生产预测等一系列的解决方案。
一切围绕集成
微软希望通过提供一个集成的解决方案,第三方和系统集成商可以基于这一套件打造打包式解决方案,让一些不同的产品能够很好地在一起发挥功效,这样的产品将会吸引消费者。这正是这一集成所在做的事, 这样就会减少让这些类型的工具合作的复杂性——至少理论上是这样。
“这一套件提供的价值在于卓越的互操作性,已完成的解决方案,既有配方又有指导书,”斯瑞西解释道。
微软举了一个例子,它谈到 Dartmouth-Hitchcock 医疗中心的一个医疗保健协调项目。被称为 ImagineCare 的解决方案正是建立在 Cortana Analytics Suite 和 Microsoft Dynamics CRM 工具的基础之上。
这个解决方案希望通过向患者提供家庭监护来测量心率、血压、睡眠模式、体重等等,并且在 Azure 云中共享这些信息,这样医护人员可以协调更好的医疗服务,还可以防止像心脏病发作这类重大医疗事件的发生。
护士可以在医疗数据仪表盘上监控一组病人的数据,在病人的数据发生整体变化时,协调更好的治疗和更好地应对,这些变化如果不及时治疗可能会带来更大的问题。斯瑞西谨慎地指出,这更多的是一种未来的理想状态,但微软希望通过将这些分散的功能用一种协作的方式集合在一起,为这些复杂项目的发展提供一个平台。
套件情结
微软用在这个套件上的是可靠实用的打包技术,那些我们多年来在微软、IBM 和 Adobe 这样的大公司身上所看到的技术,他们用这一技术把一组有些关联的产品放在一起,鼓励顾客去购买所有的产品而不是其中的一两个。
微软在 Office 套件中就万年不变地使用类似的集成手段。Adobe 在 Creative Suite 上也是如出一辙。两家公司都为套件中的产品提供了更方便的操作。
Cortana Analytics Suite 会在今年秋季晚些时候上市。斯瑞西没有说价格的事情,不过据他说,如果你想买这个套件,收费模式会更加简单,肯定比你单独购买这些产品要划算得多。
这看上去是一个挺不错的营销做法,但在现实中,根据过去几年的经验显示,消费者想要产品类别中最好的那一款,而且他们更愿意组合他们想要的或是已有的产品。
各家企业已经不想再受制于一家供应商。他们要让他们的供应商,特别是在云端,能够让各种不同的产品,不管生产商是哪一家,都能够更容易地一道工作。
这一套件属于逆势而上。时间会告诉我们消费者是否买账。
Microsoft Hopes To Unify Big Data And Analytics In Newly Announced Suite
At its Worldwide Partner Conference in Orlando,Microsoft announced the Cortana Analytics Suite. It takes the company’s machine learning, big data and analytics products and packages them together in one huge, monolithic suite.
Microsoft has put together the suite with the hope of providing a one-stop, big data and analytics solution for enterprise customers.
“Our goal was to bring integration of these pieces so customers have a comprehensive platform to build intelligent solutions,” Joseph Sirosh, corporate vice president at Microsoft, who is in charge of Azure ML told TechCrunch.
As for Cortana, which is the Microsoft voice-driven personal assistant tool in Windows 10, it’s a small part of the solution, but Sirosh says Microsoft named the suite after it because it symbolizes the contextualized intelligence that the company hopes to deliver across the entire suite.
It includes pieces like Azure ML, the company’s cloud machine learning product, PowerBI, its data visualization tool and Azure Data Catalog,a service announced just last week designed for sharing and surfacing data stores inside a company, among others. It hopes to take advantage of range of technologies such as face and speech recognition to generate a series of solutions like recommendation engines and churn forecasting.
It’s All About Integration
Microsoft expects that by providing an integrated solution, third parties and systems integrators will build packaged solutions based on the suite, and that customers will be attracted by a product with pieces designed to play nicely together. It is building in integration, thereby reducing the complexity of making these types of tools work together — at least that’s the theory.
“Where the suite provides value is the great interoperability, finished solutions, recipes and cookbooks,” Sirosh explained.
As an example, Microsoft talked about a coordinated medical care project at Dartmouth-Hitchcock Medical Center. The program, called ImagineCare, is built on top of the Cortana Analytics Suite and the Microsoft Dynamics CRM tool.
The hope is that by providing patients with home monitoring to measure things like heart rate, blood pressure, sleep patterns, weight gain and so forth, and sharing this information in the Azure cloud, they can coordinate better care and perhaps prevent a major medical event like a heart attack.
Nurses could monitor the data from a group of patients in a medical data dashboard and coordinate better care and responses to changes in the overall patient profile that could signal larger issues if left untreated. Sirosh was careful to point out that this is more of a future ideal, but Microsoft is hoping that by putting these pieces together in a coordinated fashion, it will provide a platform for these types of sophisticated projects moving forward.
Suite Emotion
What Microsoft is doing with this suite is the tried and true packaging technique, we have seen from big companies like Microsoft, IBM and Adobe for years, taking a group of somewhat-related products and putting them together to encourage customers to buy all of the products instead of just a couple.
Microsoft made billions for years delivering a similar type of integration with the Office suite. Adobe did the same thing with Creative Suite, both companies delivering ways to work more easily across the products that make up the suite.
Cortana Analytics Suite will be available later this Fall. Sirosh wouldn’t discuss pricing, but if you buy one suite, you’ll get a simpler billing model and more savings than you would get buying the individual pieces, he said.
It seems like a sound marketing practice, but in reality customers have indicated over the last several years, they want the best of breed across product categories and prefer to string together the products they want or already own.
Companies no longer want to be locked into a single vendor. They want their vendors, especially in the cloud to make it easier to make the various pieces work together, regardless of the manufacturer.
This suite bucks that trend. Time will tell if customers will bite.
来源:Techcrunch
大数据背后的事儿
导语:大数据到底带给我们的是高效有序管理体系,还是不可预测的威胁隐患?
本文作者比尔·弗兰克斯是Teradata的首席分析官,同时也是international Institute for Analytics的教员。他表达了有关大数据空间及其分析的发展趋势的见解,著有The Big Data Tidal Wave,并在最近出版了他的第二本书The Analytics Revolution。
窥探人隐私的不是数据,是人。但是这样简单的事实,人们往往很难接受。就像NSA(国家安全局)发生的丑闻,经常性的数据泄露事件和频发的电视台窃听私人通话事件,难怪人们会越来越不信任数据。91%的美国人认为,消费者已经无法阻止个人信息被其他企业收集和利用,并有61%的人希望能采取措施保护他们在网上的个人信息。无论数据是被社交媒体故意披露的,或是通过人们在网站和智能手机上留下的痕迹无意中收集的,恐怖的是,个人隐私和信息自由,甚至是民主意识都受到了威胁。
从法院受理的官司和媒体讨论的骇人设想可以轻松得出结论,大数据分析总是有害的。但是,真的是这样的吗?
利大于弊
最近,我出席了一个会议,与众多国家立法者和高管商讨如何能利用大数据、更先进的分析技术以及升级数据管理系统,从而帮助国家更有效地控制成本,减少欺诈行为并提供更高效的服务,更复杂的分析和更新的数据管理平台,提供国家服务。会上提出了隐私泄露和数据误用的问题,并引发了激烈的讨论。讨论的主题是:鉴于当权者误用和滥用数据的风险,国家收集大量数据到底是不是个好主意。
我给出了几个强大数据如何能为人们带来很多好处的例子。想想那些指派去监控那些有虐童史家庭的社会工作者,如果新来的社工能使用过去搜集的数据,孩子们就可以结束不必要的受伤,甚至死亡。在我的家乡格鲁吉亚,因为社工没有有关孩子当时面临的危险的重要信息,很多孩子因此丧失了生命。这一事件在当地引起很多关注。
某国家官员指出,获得的关注有效度与这些国家工作者收集的高度敏感信息有关。使信息容易获得意味着低收入、技术水平不高的工人可以轻松获得高度隐私和敏感的信息。这样的信息显然更容易会被滥用。但是,在这种情况下,比起被滥用可能造成的后果,这些信息对保护孩子的生命带来的好处更大。更重要的是,这些能轻松访问数据的人都很清楚,如果他们滥用数据,不但会丢了自己的工作,还会受到很严重的法律制裁(反抗一次你就没机会再继续工作了)。
这有点像驾驶。每次我们开车其实都是冒着生命危险的。在任何时候,都有可能会有人朝我们撞过来撞死我们,即使我们可能什么都没做错。发生这样的事情确实很可悲,但它发生的几率太小了,以至于我们都可以接受这种风险。而从中我们获取了许多好处,我们能自由去任何地方,其好处足以弥补可能发生的风险。没有人会为了阻止每年发生的大量完全可以避免的车祸夺命案而去建议禁止汽车上路。整个社会已经达成共识,相比造成的风险,开车带来的好处多太多了。
我们在审视大数据及其分析时也应采纳同样的方法。利用大数据带来的好处无疑是是巨大的,无论我们如何小心,然而,同样的数据有时可能会被滥用。我们要做的应该是尽量减少数据滥用的发生,让处罚严重到人们因怕惩罚而不敢去尝试。如果州政府和其他组织能够发挥利用大数据的积极的部分,社会整体会变得越来越好。
via VB, 快鲤鱼翻译,转载标明出处

 大数据
大数据
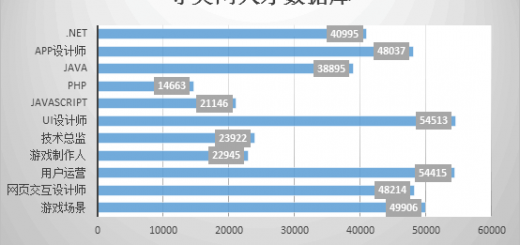 大数据
大数据
 大数据
大数据
 大数据
大数据
 大数据
大数据

 大数据
大数据
 大数据
大数据
 大数据
大数据
 大数据
大数据
 大数据
大数据



 扫一扫 加微信
hrtechchina
扫一扫 加微信
hrtechchina

